FG-CLIP 2: 为细粒度跨模态理解而生的下一代VLM,8大类29项任务双语性能全球第一
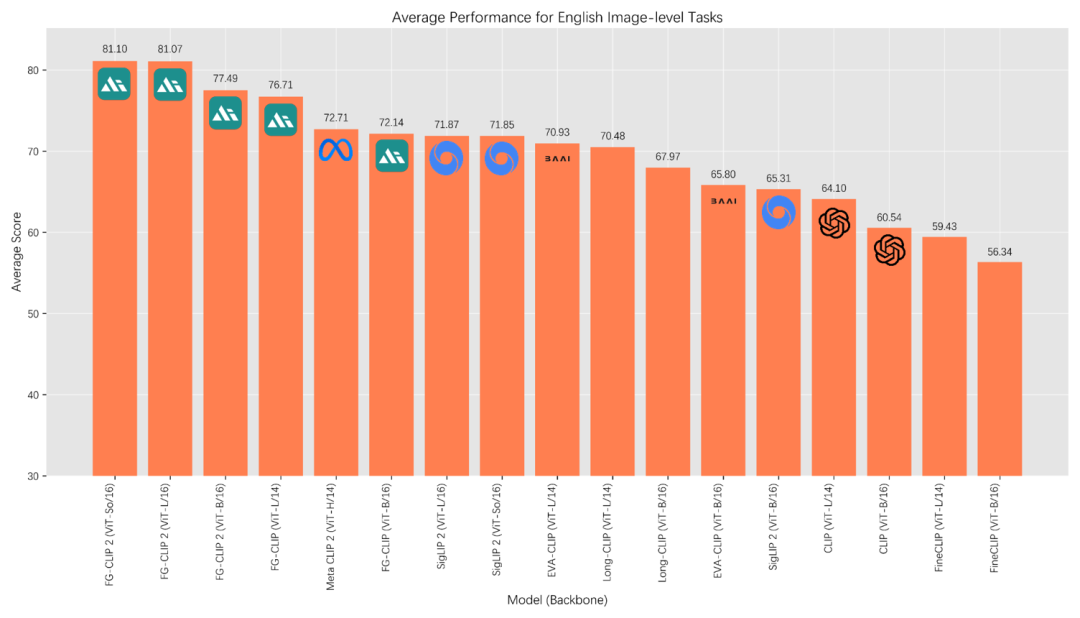
OpenAI 的 CLIP 模型是 Foundation Model 的一个里程碑式成就,它成功地证明了通过大规模图文数据的对比学习,可以让 AI 模型掌握跨越视觉和语言的泛化关联能力,为零样本识别、多模态大模型、图像生成,以及搜索、推荐、办公、安防等下游模型和应用奠定了坚实的基础 ,在很大程度上解决了让 AI “看见”并大致理解图文内容的问题。以 CLIP 为代表的第一代跨模态模型,其核心优势在于宏观主体的理解,例如识别出“公园里的一只狗”,但当面对需要精确细节认知的任务时,其局限性便显现出来。